深度度量学习解决的是什么样的问题?
分类、识别与验证 Classification vs. Recognition vs. Verification
考虑一个人脸识别的例子,验证(Verification)便是输入脸部图像与相应的验证信息(如PID、姓名等),输出他们是否匹配。这通常被称为1对1问题,我们只需要关注一个人和他提供的相应信息是否相符即可。
而识别则是输入脸部图像,我们需要从一个含有K个人身份信息的数据库中找出与输入图片相匹配的ID等信息,并将其输出,若不存在则判断为不属于这K个人中的任何一个。
很显然,后者的难度更高,它是一个1对K的问题。假如我们的算法可以在1:1验证时达到99%的正确率,那么在1:K面前,这1%的犯错几率会被放大K倍。如果你的数据库有上百个人,那么想得到一个可接受的误差,你可能需要一个正确率高达99.9%的验证模型。
从分类器的角度来看,将每个人的脸部作为一个class来执行分类任务并要求极高的正确率,这是具有很大挑战性的。
原因有如下几点:
-
分类器一般在大规模的数据集上训练从而获得较高的性能,而对于像人脸这样的数据,我们一般无法针对每个人收集大量关于此人脸部的图像
-
不同class之间相似度较高时,作为分类问题我们一般需要更高像素的图像数据,从而使模型学到细、粒度更高的特征,这在一定程度上增加了训练开销
-
当有新的class加入,比如数据库添加了一位新成员的身份信息,由于是未学习的新class我们需要重新训练已有的模型。这在实际应用场景中是非常低效的
因此,对于人脸识别等task,我们想要通过单单一张或少数的几张图片,让模型获得正确识别的能力。而深度学习在只有少数个学习样本时并不能体现出很好的性能,这就是经典的Few-shot Learning问题。
改变学习目标 Learn the Metric
既然作为常规的分类问题无法满足我们的需求,改变学习目标,以更巧妙的方式完成任务不妨是一种选择。深度度量学习(Deep Metric Learning)就是萌生于这样的思想,通过学习相似度指标(Similarity,有时为欧氏距离Distance),以基于相似度的代价函数代替传统的Cross Entropy。(这里沿用一下自己研究会的Slide~)
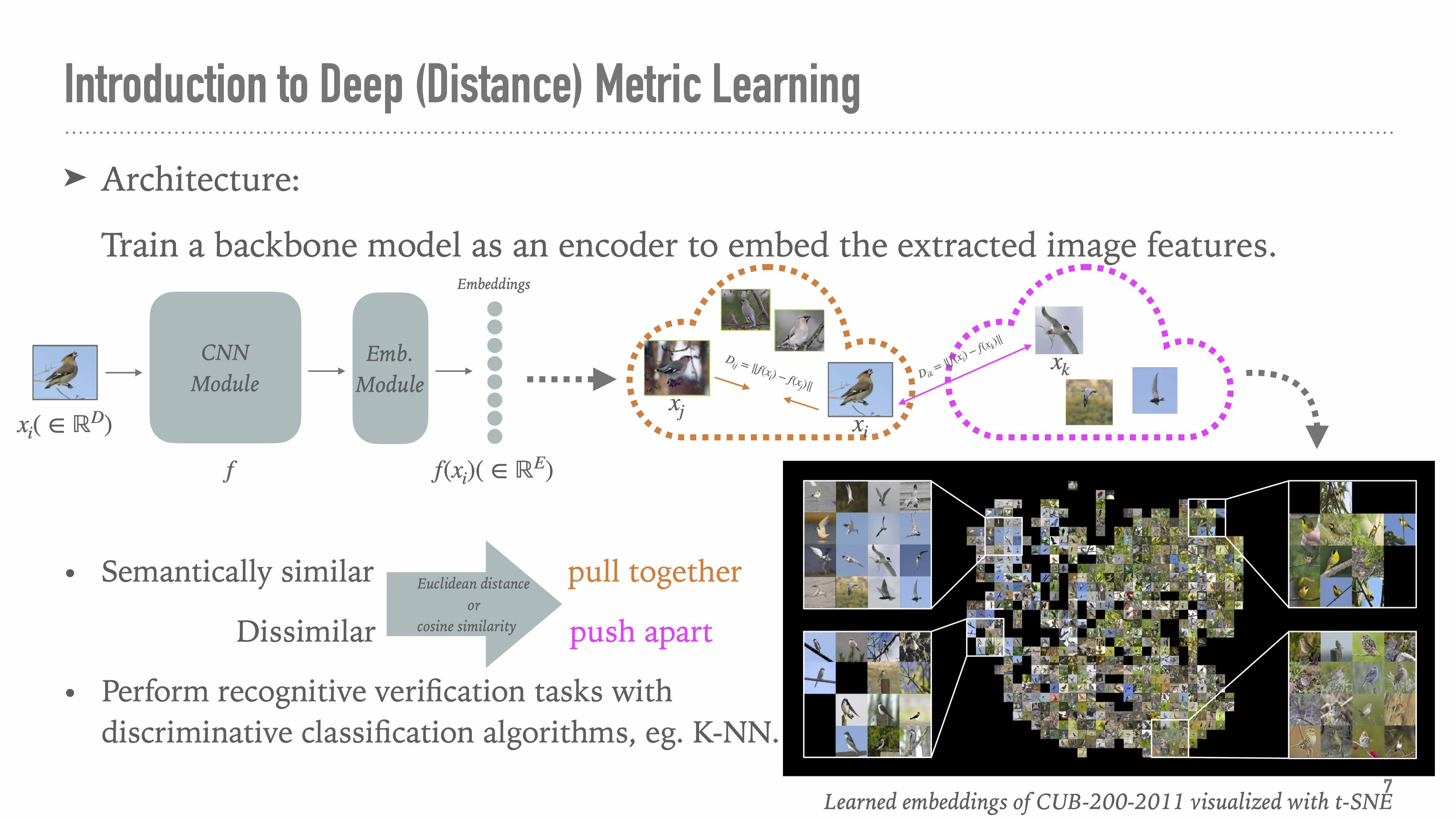
关于度量学习的其他说法,嵌入学习(Embedding Learning)、监督表示学习(Supervised Representation Learning)都是同义词,简单来说就是通过数据,学习一个从原始的数据空间(图像,文字,句子等)到高维欧氏空间(或者球面)中的映射。这个映射的目标就是同类近,异类远;或者同类相似度高,异类相似度低。
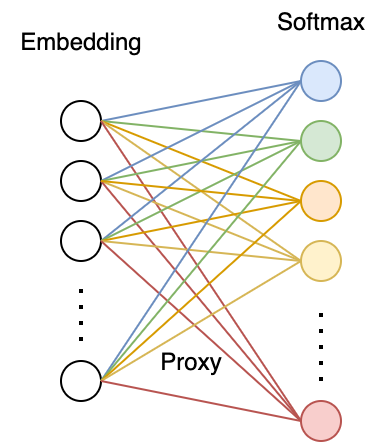
度量学习的方法 Pair-based vs. Proxy-based
Metric Learning的方法主要有两大分支:pair-based 和 proxy-based。
pair-based是基于真实的样本对,比如经典的Contrastive Loss和Triplet Loss,以及基于他们改善而来的N-pair Loss,MS Loss等。
而proxy-based则是利用proxy去管理具体class的特征,或者可以说是样本特征的中心点,比如说Proxy-NCA,Proxy-Anchor等。proxy是一个非常宽泛的概念,在SoftMax形式的代价函数中,它是FC层参数矩阵的列;在memory的方法中,它是存储在memory中的特征。